2025

Game-TARS: Pretrained Foundation Models for Scalable Generalist Multimodal Game Agents
Bytedance Seed
arXiv 2025
We present Game-TARS, a generalist game agent trained with a unified, scalable action space anchored to human-aligned native keyboard–mouse inputs. Unlike API- or GUI-based approaches, this paradigm enables large-scale continual pre-training across heterogeneous domains, including OS, web, and simulation games. Game-TARS is pre-trained on over 500B tokens with diverse trajectories and multimodal data. Key techniques include a decaying continual loss to reduce causal confusion and an efficient Sparse-Thinking strategy that balances reasoning depth and inference cost. Experiments show that Game-TARS achieves about 2 times the success rate over the previous sota model on open-world Minecraft tasks, is close to the generality of fresh humans in unseen web 3d games, and outperforms GPT-5, Gemini-2.5-Pro, and Claude-4-Sonnet in FPS benchmarks. Scaling results on training-time and test-time confirm that the unified action space sustains improvements when scaled to cross-game and multimodal data. Our results demonstrate that simple, scalable action representations combined with large-scale pre-training provide a promising path toward generalist agents with broad problem-solving abilities.
Game-TARS: Pretrained Foundation Models for Scalable Generalist Multimodal Game Agents
Bytedance Seed
arXiv 2025
We present Game-TARS, a generalist game agent trained with a unified, scalable action space anchored to human-aligned native keyboard–mouse inputs. Unlike API- or GUI-based approaches, this paradigm enables large-scale continual pre-training across heterogeneous domains, including OS, web, and simulation games. Game-TARS is pre-trained on over 500B tokens with diverse trajectories and multimodal data. Key techniques include a decaying continual loss to reduce causal confusion and an efficient Sparse-Thinking strategy that balances reasoning depth and inference cost. Experiments show that Game-TARS achieves about 2 times the success rate over the previous sota model on open-world Minecraft tasks, is close to the generality of fresh humans in unseen web 3d games, and outperforms GPT-5, Gemini-2.5-Pro, and Claude-4-Sonnet in FPS benchmarks. Scaling results on training-time and test-time confirm that the unified action space sustains improvements when scaled to cross-game and multimodal data. Our results demonstrate that simple, scalable action representations combined with large-scale pre-training provide a promising path toward generalist agents with broad problem-solving abilities.
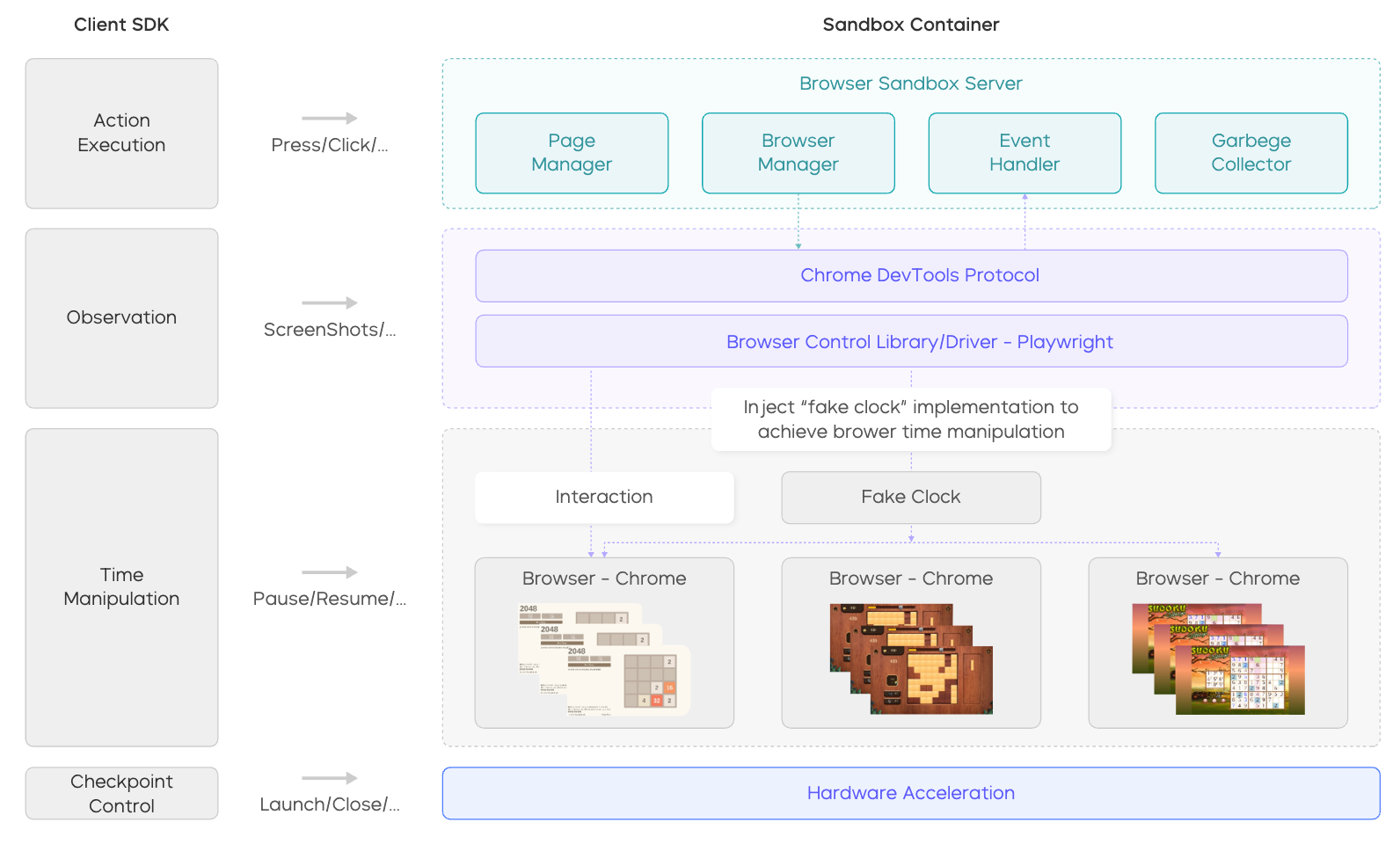
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Bytedance Seed
arXiv 2025
In this technical report, we present UI-TARS-2, a native GUI-centered agent model that addresses these challenges through a systematic training methodology: a data flywheel for scalable data generation, a stabilized multi-turn RL framework, a hybrid GUI environment that integrates file systems and terminals, and a unified sandbox platform for large-scale rollouts. Empirical evaluation demonstrates that UI-TARS-2 achieves significant improvements over its predecessor UI-TARS-1.5. On GUI benchmarks, it reaches 88.2 on Online-Mind2Web, 47.5 on OSWorld, 50.6 on WindowsAgentArena, and 73.3 on AndroidWorld, outperforming strong baselines such as Claude and OpenAI agents...
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Bytedance Seed
arXiv 2025
In this technical report, we present UI-TARS-2, a native GUI-centered agent model that addresses these challenges through a systematic training methodology: a data flywheel for scalable data generation, a stabilized multi-turn RL framework, a hybrid GUI environment that integrates file systems and terminals, and a unified sandbox platform for large-scale rollouts. Empirical evaluation demonstrates that UI-TARS-2 achieves significant improvements over its predecessor UI-TARS-1.5. On GUI benchmarks, it reaches 88.2 on Online-Mind2Web, 47.5 on OSWorld, 50.6 on WindowsAgentArena, and 73.3 on AndroidWorld, outperforming strong baselines such as Claude and OpenAI agents...
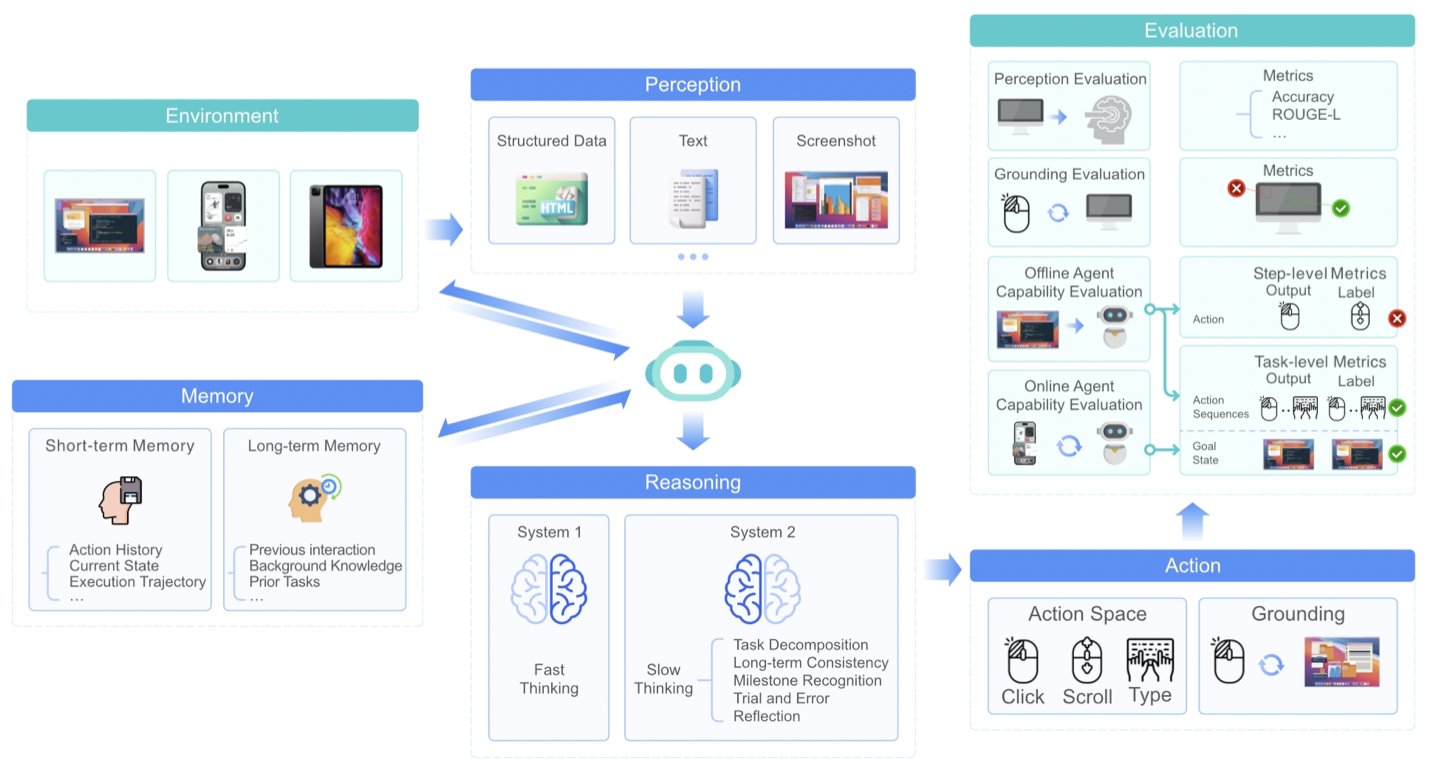
UI-TARS-1.5
Bytedance Seed
arXiv 2025
UI-TARS-1.5 is an open-source multimodal agent built upon a powerful vision-language model. It is capable of effectively performing diverse tasks within virtual worlds. Leveraging the foundational architecture introduced in our recent paper, UI-TARS-1.5 integrates advanced reasoning enabled by reinforcement learning. This allows the model to reason through its thoughts before taking action, significantly enhancing its performance and adaptability, particularly in inference-time scaling. Our new 1.5 version achieves state-of-the-art results across a variety of standard benchmarks, demonstrating strong reasoning capabilities and notable improvements over prior models.
UI-TARS-1.5
Bytedance Seed
arXiv 2025
UI-TARS-1.5 is an open-source multimodal agent built upon a powerful vision-language model. It is capable of effectively performing diverse tasks within virtual worlds. Leveraging the foundational architecture introduced in our recent paper, UI-TARS-1.5 integrates advanced reasoning enabled by reinforcement learning. This allows the model to reason through its thoughts before taking action, significantly enhancing its performance and adaptability, particularly in inference-time scaling. Our new 1.5 version achieves state-of-the-art results across a variety of standard benchmarks, demonstrating strong reasoning capabilities and notable improvements over prior models.
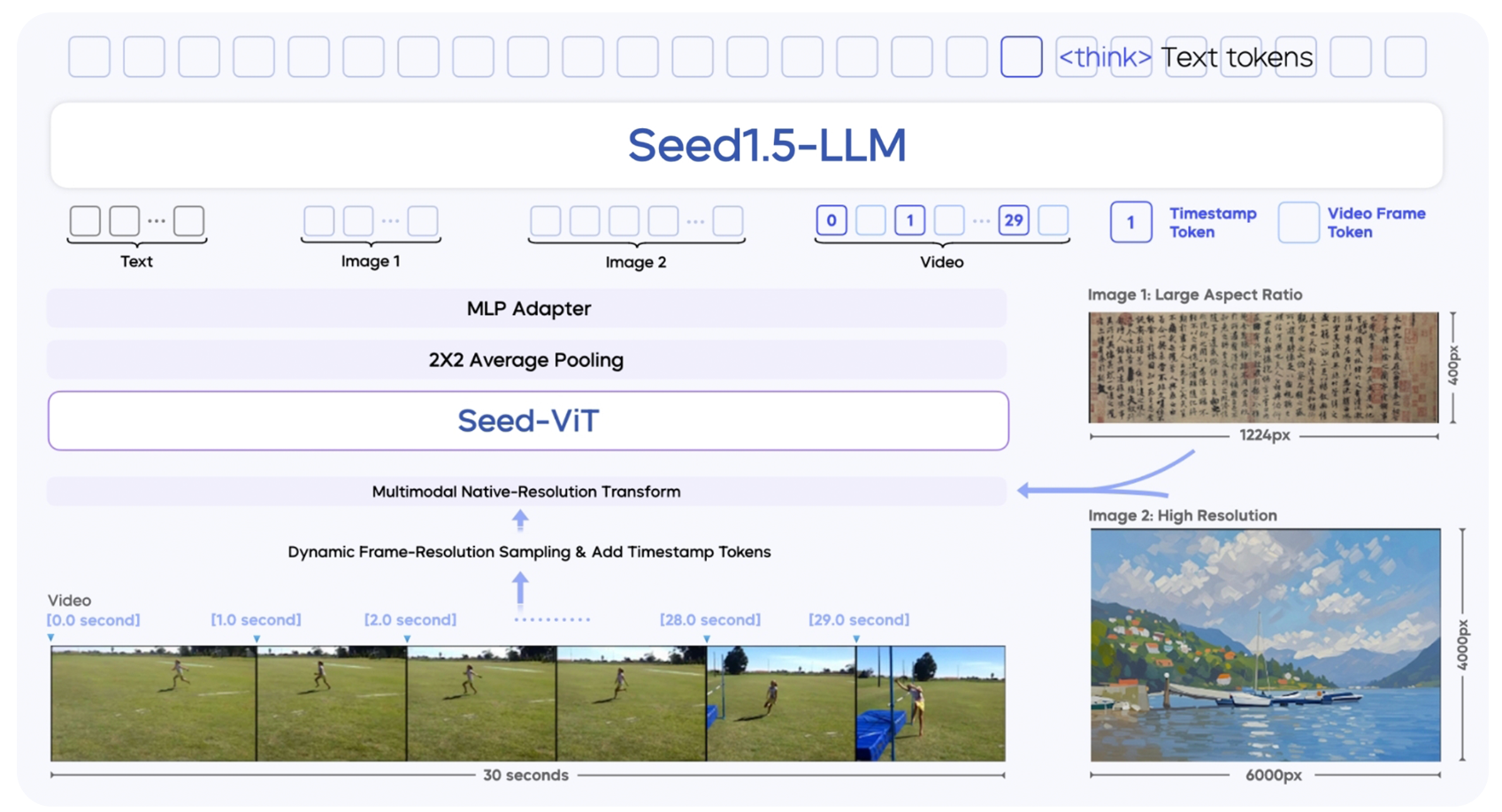
Seed1.5-VL Technical Report
Bytedance Seed
Technical Report 2025
We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research.
Seed1.5-VL Technical Report
Bytedance Seed
Technical Report 2025
We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research.
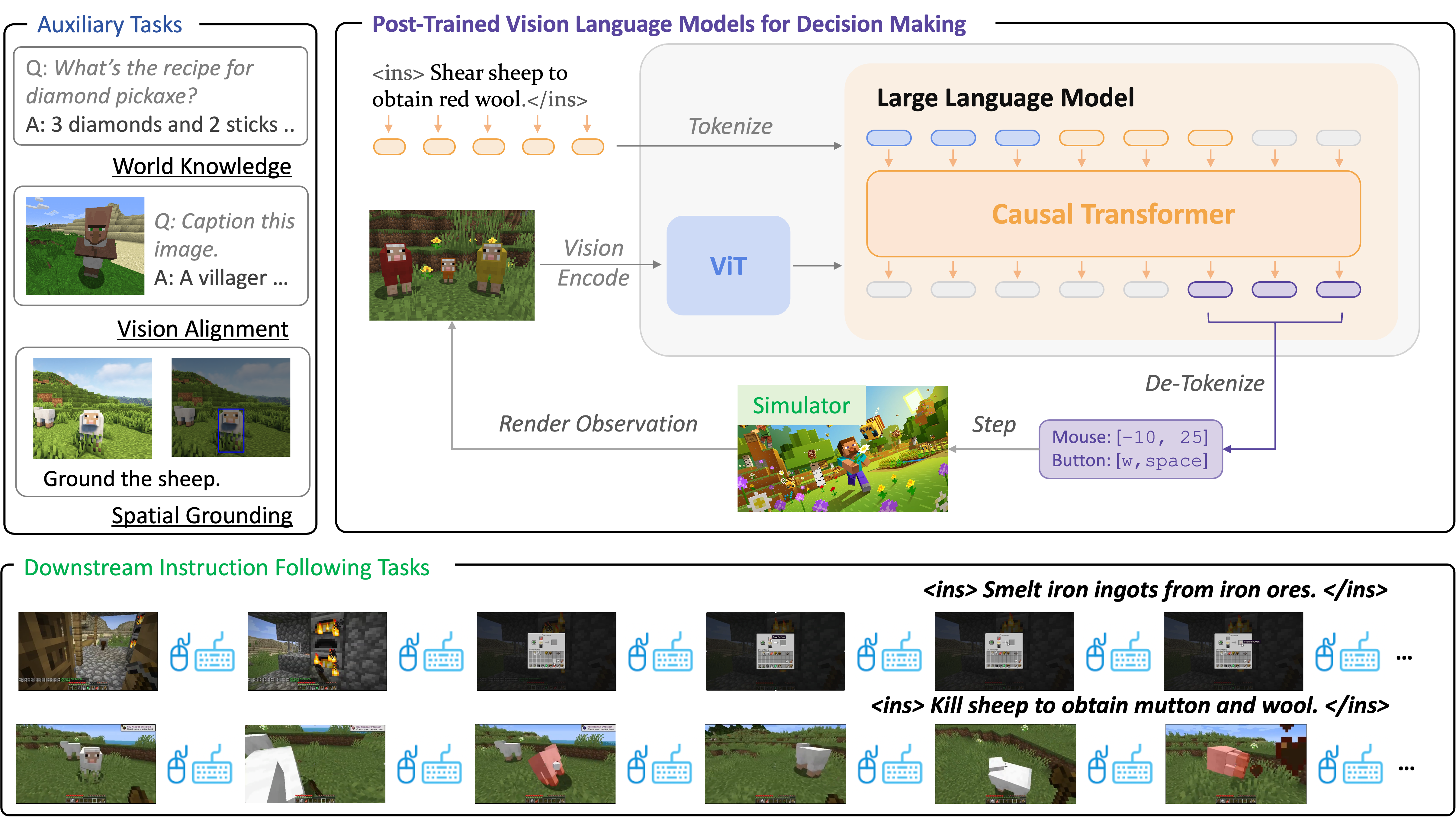
JARVIS-VLA: Post-Training Large-Scale Vision Language Models to Play Visual Games with Keyboards and Mouse
Muyao Li*, Zihao Wang*, Kaichen He, Xiaojian Ma, Yitao Liang (* equal contribution)
ACL Findings 2025
Visual Language Action (VLA) models, pretrained on large-scale web datasets, have shown promise in decision-making tasks. However, previous work has primarily focused on action post-training, often neglecting enhancements to the foundational model itself. In response, we introduce a novel approach, Act from Visual Language Post-Training, which refines Visual Language Models (VLMs) through visual and linguistic guidance in a self-supervised manner. This enhancement improves the models' capabilities in world knowledge, visual recognition, and spatial grounding in open-world environments. Following the above post-training paradigms, we obtain the first VLA models in Minecraft that can follow human instructions on over 1k different atomic tasks, including crafting, smelting, cooking, mining, and killing.
JARVIS-VLA: Post-Training Large-Scale Vision Language Models to Play Visual Games with Keyboards and Mouse
Muyao Li*, Zihao Wang*, Kaichen He, Xiaojian Ma, Yitao Liang (* equal contribution)
ACL Findings 2025
Visual Language Action (VLA) models, pretrained on large-scale web datasets, have shown promise in decision-making tasks. However, previous work has primarily focused on action post-training, often neglecting enhancements to the foundational model itself. In response, we introduce a novel approach, Act from Visual Language Post-Training, which refines Visual Language Models (VLMs) through visual and linguistic guidance in a self-supervised manner. This enhancement improves the models' capabilities in world knowledge, visual recognition, and spatial grounding in open-world environments. Following the above post-training paradigms, we obtain the first VLA models in Minecraft that can follow human instructions on over 1k different atomic tasks, including crafting, smelting, cooking, mining, and killing.
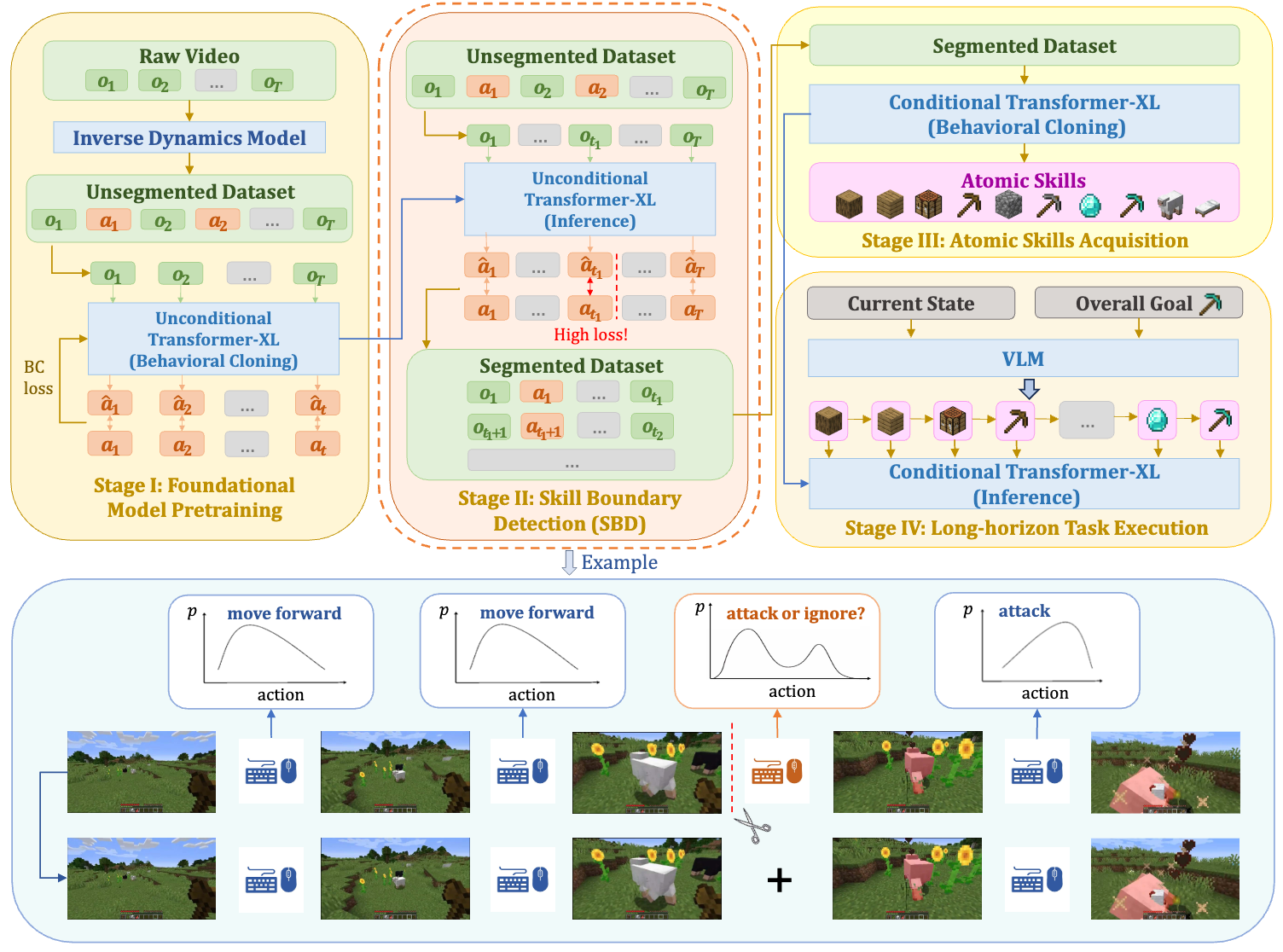
Open-World Skill Discovery from Unsegmented Demonstrations
Jingwen Deng*, Zihao Wang*, Anji Liu, Yitao Liang (* equal contribution)
ICCV 2025
Learning skills in open-world environments is essential for developing agents capable of handling a variety of tasks by combining basic skills. Online demonstration videos are typically long but unsegmented, making them difficult to segment and label with skill identifiers. Unlike existing methods that rely on sequence sampling or human labeling, we have developed a self-supervised learning-based approach to segment these long videos into a series of semantic-aware and skill-consistent segments. Drawing inspiration from human cognitive event segmentation theory, we introduce Skill Boundary Detection (SBD), an annotation-free temporal video segmentation algorithm. SBD detects skill boundaries in a video by leveraging prediction errors from a pretrained unconditional action-prediction model.
Open-World Skill Discovery from Unsegmented Demonstrations
Jingwen Deng*, Zihao Wang*, Anji Liu, Yitao Liang (* equal contribution)
ICCV 2025
Learning skills in open-world environments is essential for developing agents capable of handling a variety of tasks by combining basic skills. Online demonstration videos are typically long but unsegmented, making them difficult to segment and label with skill identifiers. Unlike existing methods that rely on sequence sampling or human labeling, we have developed a self-supervised learning-based approach to segment these long videos into a series of semantic-aware and skill-consistent segments. Drawing inspiration from human cognitive event segmentation theory, we introduce Skill Boundary Detection (SBD), an annotation-free temporal video segmentation algorithm. SBD detects skill boundaries in a video by leveraging prediction errors from a pretrained unconditional action-prediction model.
ROCKET-1: Master Open-World Interaction with Visual-Temporal Context Prompting
Shaofei Cai, Zihao Wang, Kewei Lian, Zhancun Mu, Xiaojian Ma, Anji Liu, Yitao Liang
CVPR 2025
We propose visual-temporal context prompting, a novel communication protocol between VLMs and policy models. This protocol leverages object segmentation from past observations to guide policy-environment interactions. Using this approach, we train ROCKET-1, a low-level policy that predicts actions based on concatenated visual observations and segmentation masks, supported by real-time object tracking from SAM-2. Our method unlocks the potential of VLMs, enabling them to tackle complex tasks that demand spatial reasoning.
ROCKET-1: Master Open-World Interaction with Visual-Temporal Context Prompting
Shaofei Cai, Zihao Wang, Kewei Lian, Zhancun Mu, Xiaojian Ma, Anji Liu, Yitao Liang
CVPR 2025
We propose visual-temporal context prompting, a novel communication protocol between VLMs and policy models. This protocol leverages object segmentation from past observations to guide policy-environment interactions. Using this approach, we train ROCKET-1, a low-level policy that predicts actions based on concatenated visual observations and segmentation masks, supported by real-time object tracking from SAM-2. Our method unlocks the potential of VLMs, enabling them to tackle complex tasks that demand spatial reasoning.
2024

GROOT-2: Weakly Supervised Multi-Modal Instruction Following Agents
Shaofei Cai*, Bowei Zhang*, Zihao Wang, Xiaojian Ma, Anji Liu, Yitao Liang (* equal contribution)
ICLR 2025
We frame the problem as a semi-supervised learning task and introduce GROOT-2, a multimodal instructable agent trained using a novel approach that combines weak supervision with latent variable models. Our method consists of two key components: constrained self-imitating, which utilizes large amounts of unlabeled demonstrations to enable the policy to learn diverse behaviors, and human intention alignment, which uses a smaller set of labeled demonstrations to ensure the latent space reflects human intentions.
GROOT-2: Weakly Supervised Multi-Modal Instruction Following Agents
Shaofei Cai*, Bowei Zhang*, Zihao Wang, Xiaojian Ma, Anji Liu, Yitao Liang (* equal contribution)
ICLR 2025
We frame the problem as a semi-supervised learning task and introduce GROOT-2, a multimodal instructable agent trained using a novel approach that combines weak supervision with latent variable models. Our method consists of two key components: constrained self-imitating, which utilizes large amounts of unlabeled demonstrations to enable the policy to learn diverse behaviors, and human intention alignment, which uses a smaller set of labeled demonstrations to ensure the latent space reflects human intentions.
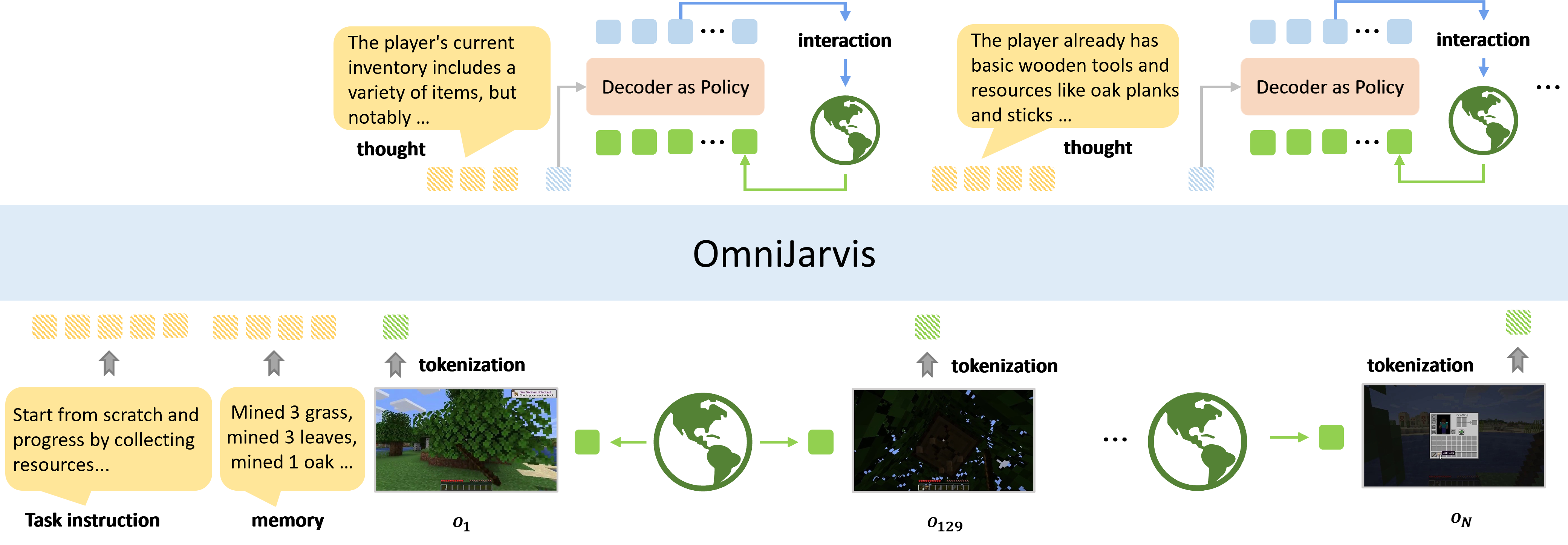
OmniJARVIS: Unified Vision-Language-Action Tokenization Enables Open-World Instruction Following Agents
Zihao Wang, Shaofei Cai, Zhancun Mu, Haowei Lin, Ceyao Zhang, Xuejie Liu, Qing Li, Anji Liu, Xiaojian Ma, Yitao Liang
NeurIPS 2024
An end-to-end open-ended agent based on Vision-Language-Action (VLA) models with self-supervised behavior tokenizer, that can answer questions and follow instructions in open-world Minecraft.
OmniJARVIS: Unified Vision-Language-Action Tokenization Enables Open-World Instruction Following Agents
Zihao Wang, Shaofei Cai, Zhancun Mu, Haowei Lin, Ceyao Zhang, Xuejie Liu, Qing Li, Anji Liu, Xiaojian Ma, Yitao Liang
NeurIPS 2024
An end-to-end open-ended agent based on Vision-Language-Action (VLA) models with self-supervised behavior tokenizer, that can answer questions and follow instructions in open-world Minecraft.
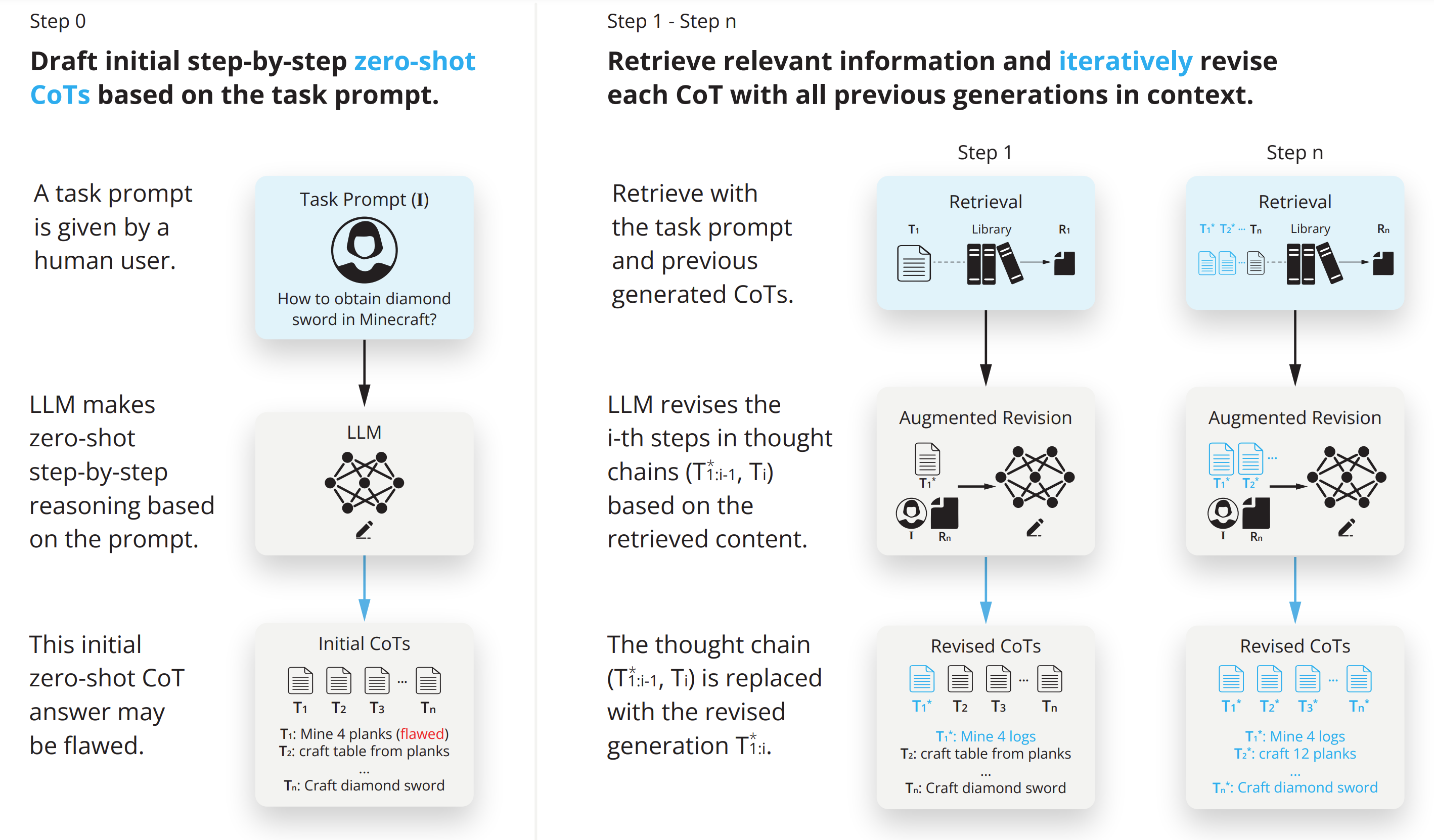
RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation
Zihao Wang, Anji Liu, Haowei Lin, Jiaqi Li, Xiaojian Ma, Yitao Liang
NeurIPS Workshop 2024
An agent with retrieval-augmented thought that can conduct code generation, math reasoning, embodied planning and open-ended question answering.
RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation
Zihao Wang, Anji Liu, Haowei Lin, Jiaqi Li, Xiaojian Ma, Yitao Liang
NeurIPS Workshop 2024
An agent with retrieval-augmented thought that can conduct code generation, math reasoning, embodied planning and open-ended question answering.
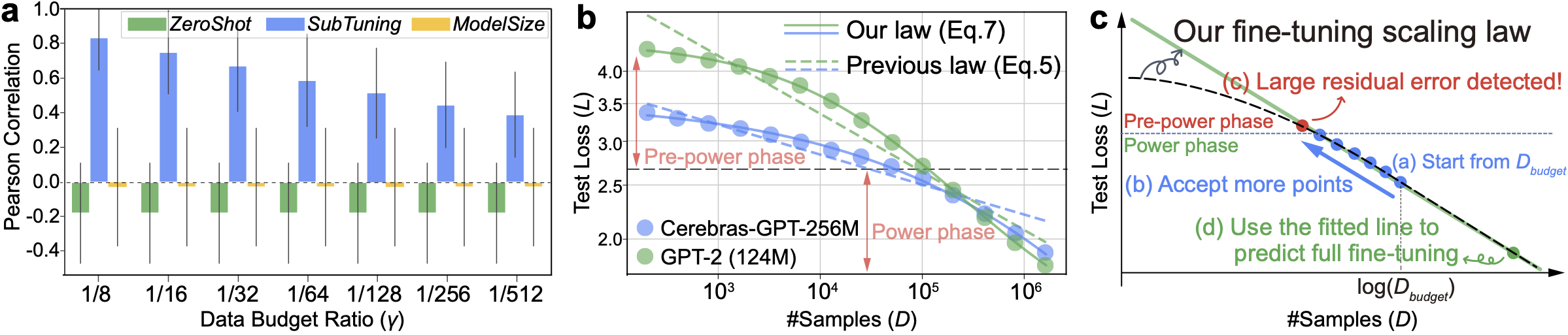
Selecting Large Language Model to Fine-tune via Rectified Scaling Law
Haowei Lin, Baizhou Huang, Haotian Ye, Qinyu Chen, Zihao Wang, Sujian Li, Jianzhu Ma, Xiaojun Wan, James Zou, Yitao Liang
ICML 2024
This work forms this resource-constrained selection task into predicting fine-tuning performance and introduces the concept of "pre-learned data size" into the Rectified Scaling Law, which overcomes theoretical limitations and fits experimental results much better.
Selecting Large Language Model to Fine-tune via Rectified Scaling Law
Haowei Lin, Baizhou Huang, Haotian Ye, Qinyu Chen, Zihao Wang, Sujian Li, Jianzhu Ma, Xiaojun Wan, James Zou, Yitao Liang
ICML 2024
This work forms this resource-constrained selection task into predicting fine-tuning performance and introduces the concept of "pre-learned data size" into the Rectified Scaling Law, which overcomes theoretical limitations and fits experimental results much better.
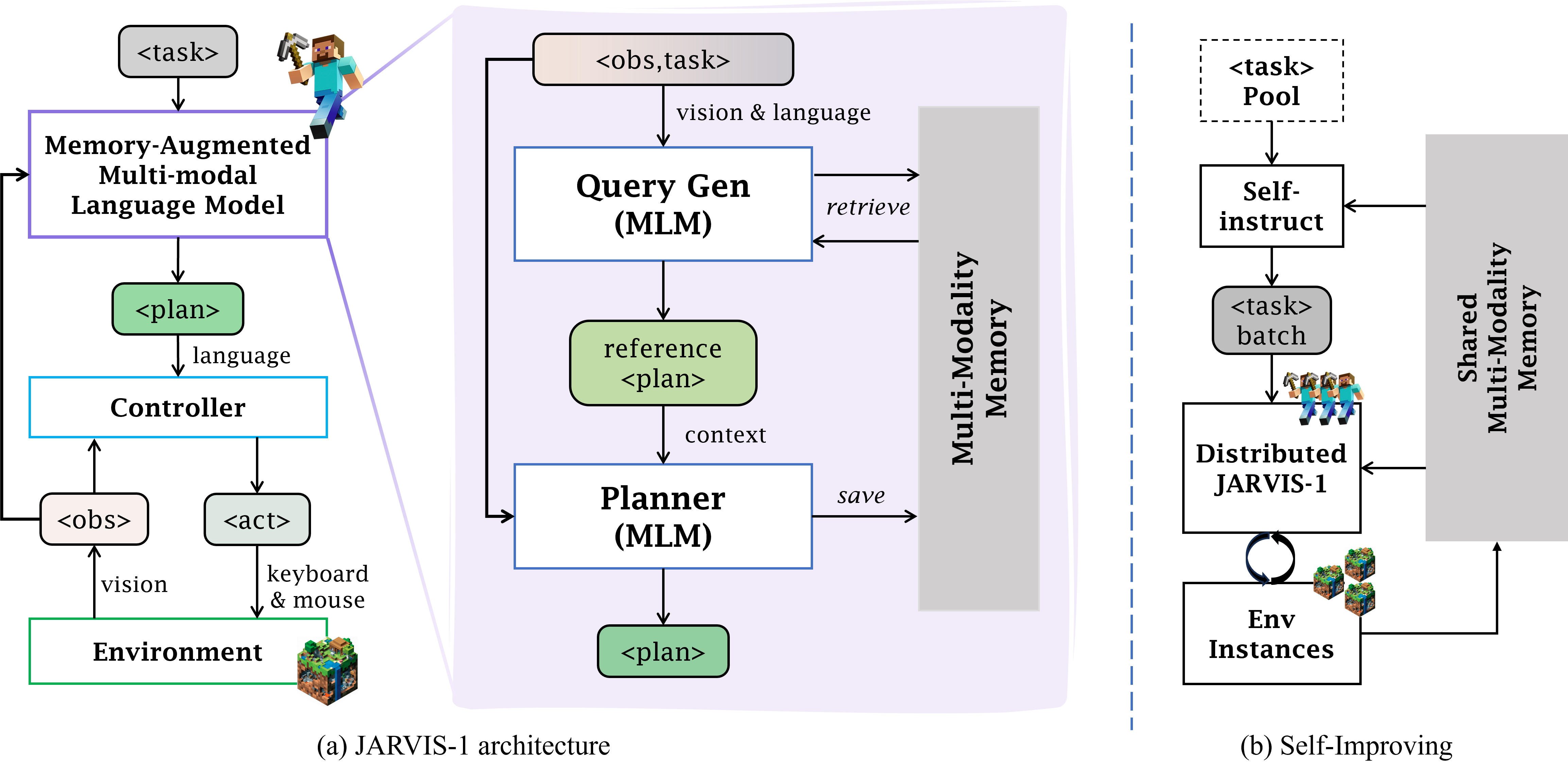
JARVIS-1: Open-World Multi-task Agents with Memory-Augmented Multimodal Language Models
Zihao Wang, Shaofei Cai, Anji Liu, Yonggang Jin, Jinbing Hou, Bowei Zhang, Haowei Lin, Zhaofeng He, Zilong Zheng, Yaodong Yang, Xiaojian Ma, Yitao Liang
T-PAMI 2024
A multi-task agent that can self-improve in open-ended Minecraft and accomplish up to 200+ tasks.
JARVIS-1: Open-World Multi-task Agents with Memory-Augmented Multimodal Language Models
Zihao Wang, Shaofei Cai, Anji Liu, Yonggang Jin, Jinbing Hou, Bowei Zhang, Haowei Lin, Zhaofeng He, Zilong Zheng, Yaodong Yang, Xiaojian Ma, Yitao Liang
T-PAMI 2024
A multi-task agent that can self-improve in open-ended Minecraft and accomplish up to 200+ tasks.
2023
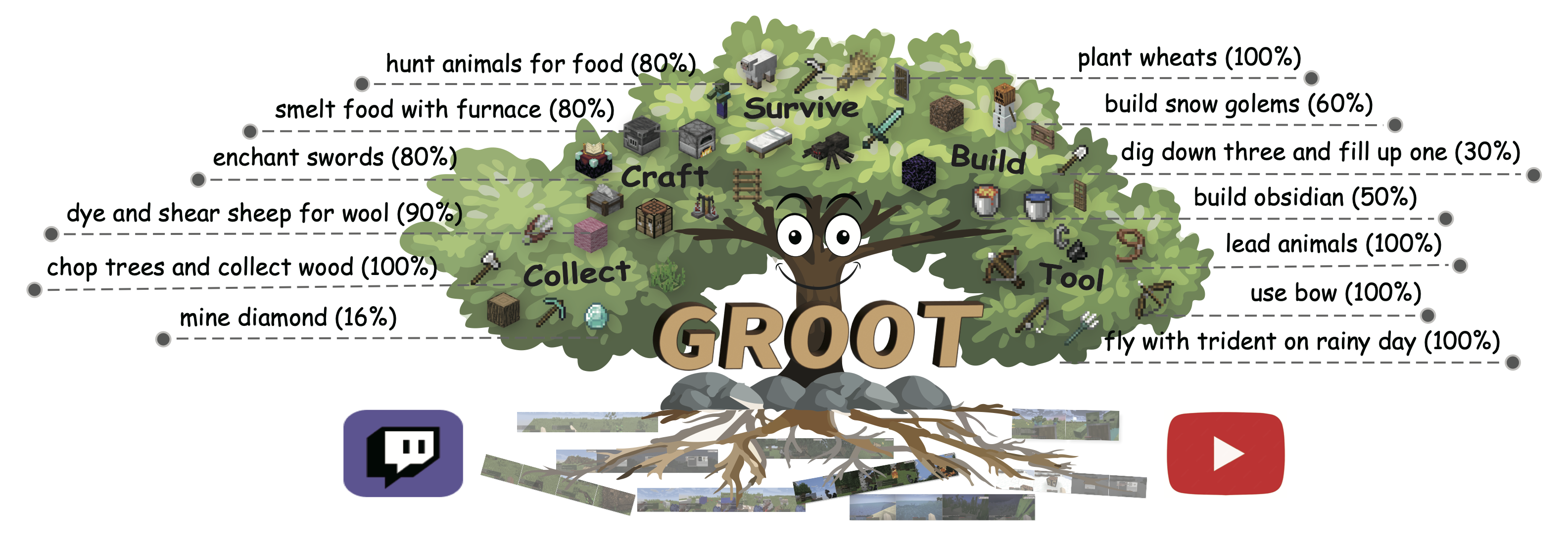
GROOT: Learning to Follow Instructions by Watching Gameplay Videos
Shaofei Cai, Bowei Zhang, Zihao Wang, Xiaojian Ma, Anji Liu, Yitao Liang
ICLR 2024 Spotlight
This work proposes to follow reference videos as instructions, which offer expressive goal specifications while eliminating the need for expensive text-gameplay annotations, and implements the agent GROOT in a simple yet effective encoder-decoder architecture based on causal transformers.
GROOT: Learning to Follow Instructions by Watching Gameplay Videos
Shaofei Cai, Bowei Zhang, Zihao Wang, Xiaojian Ma, Anji Liu, Yitao Liang
ICLR 2024 Spotlight
This work proposes to follow reference videos as instructions, which offer expressive goal specifications while eliminating the need for expensive text-gameplay annotations, and implements the agent GROOT in a simple yet effective encoder-decoder architecture based on causal transformers.
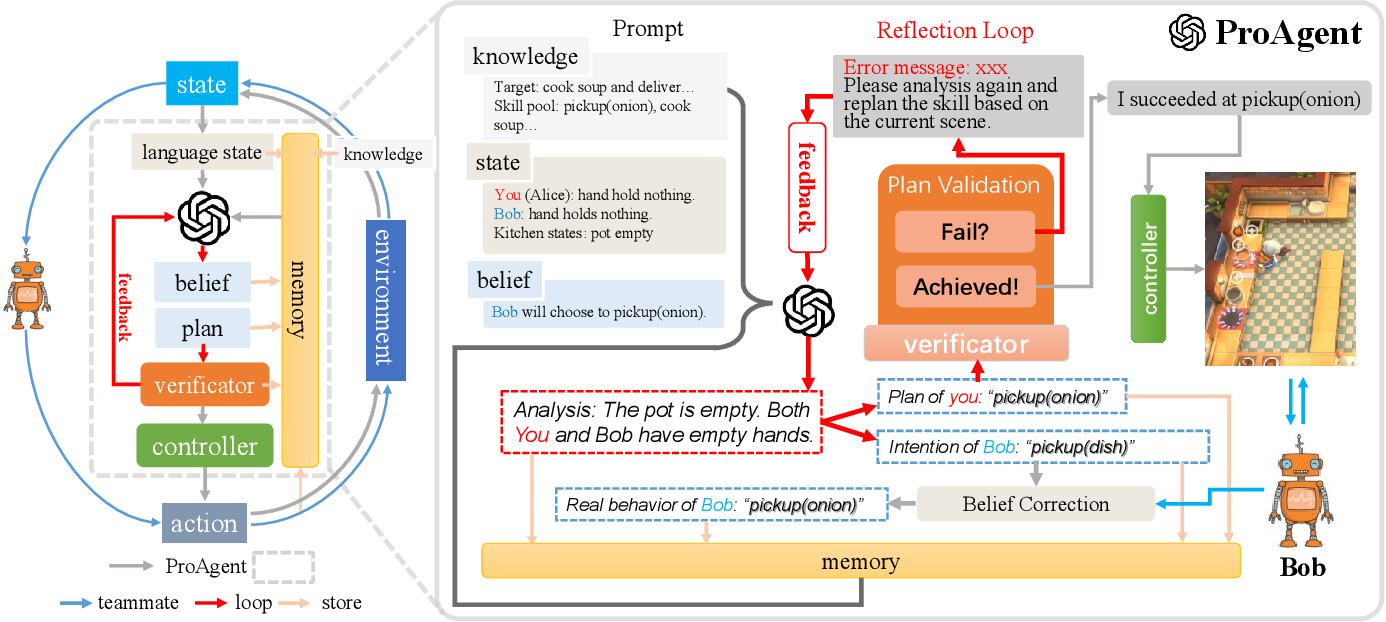
ProAgent: Building Proactive Cooperative AI with Large Language Models
Ceyao Zhang, Kaijie Yang, Siyi Hu, Zihao Wang, Guanghe Li, Yihang Sun, Cheng Zhang, Zhaowei Zhang, Anji Liu, Song-Chun Zhu, Xiaojun Chang, Junge Zhang, Feng Yin, Yitao Liang, Yaodong Yang
AAAI 2024 Oral
ProAgent is a novel framework that harnesses large language models (LLMs) to create proactive agents capable of dynamically adapting their behavior to enhance cooperation with teammates, and exhibits a high degree of modularity and interpretability, making it easily integrated into various of coordination scenarios.
ProAgent: Building Proactive Cooperative AI with Large Language Models
Ceyao Zhang, Kaijie Yang, Siyi Hu, Zihao Wang, Guanghe Li, Yihang Sun, Cheng Zhang, Zhaowei Zhang, Anji Liu, Song-Chun Zhu, Xiaojun Chang, Junge Zhang, Feng Yin, Yitao Liang, Yaodong Yang
AAAI 2024 Oral
ProAgent is a novel framework that harnesses large language models (LLMs) to create proactive agents capable of dynamically adapting their behavior to enhance cooperation with teammates, and exhibits a high degree of modularity and interpretability, making it easily integrated into various of coordination scenarios.
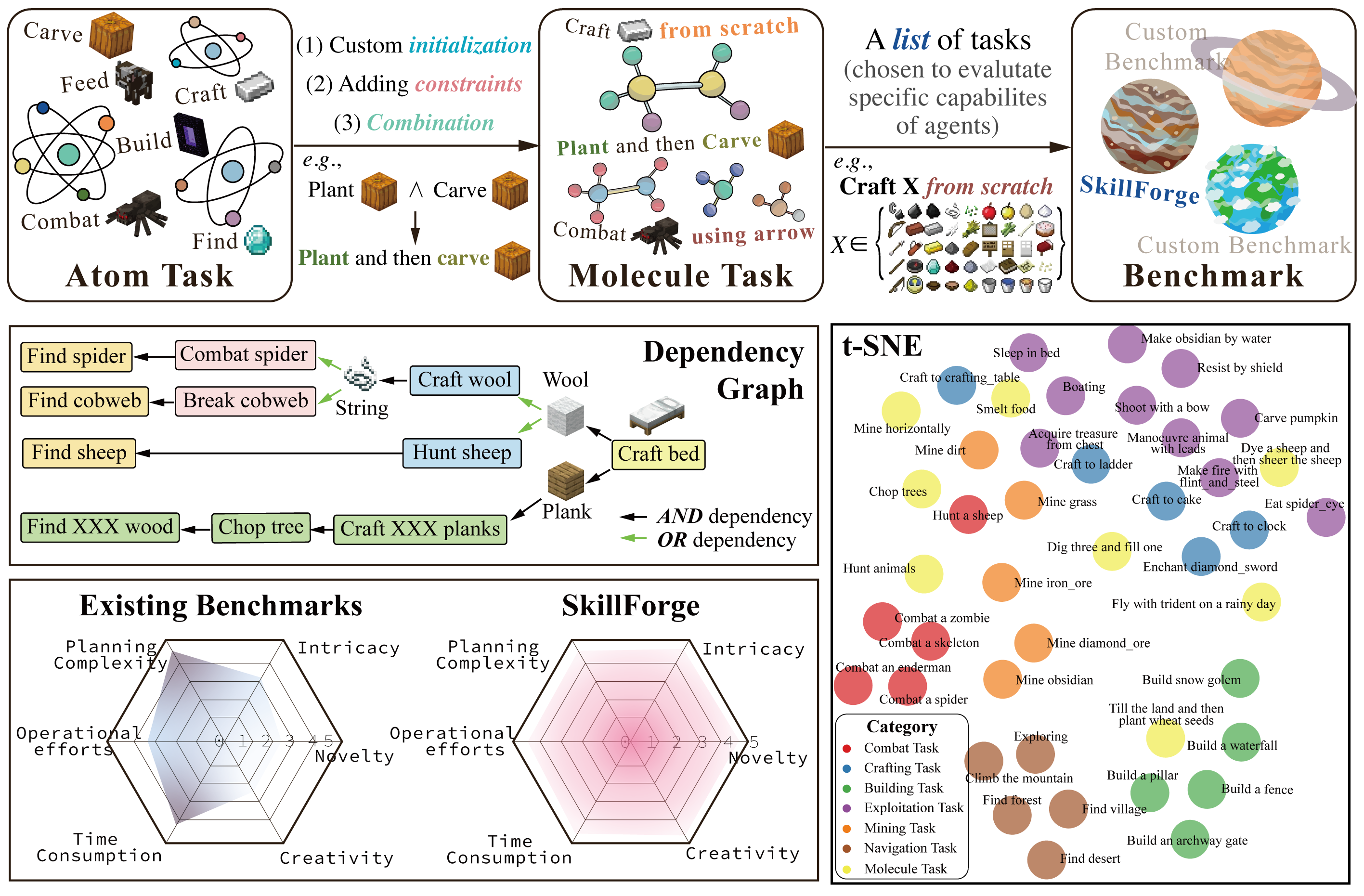
MCU: An Evaluation Framework for Open-Ended Game Agents
Xinyue Zheng, Haowei Lin, Kaichen He, Zihao Wang, Zilong Zheng, Yitao Liang
ICML Spotlight 2025
Minecraft Universe is introduced, a comprehensive evaluation framework set within the open-world video game Minecraft that combines a task composition mechanism capable of generating infinite diverse tasks with varying difficulty and a general evaluation framework that achieves 91.5% alignment with human ratings for open-ended task assessment
MCU: An Evaluation Framework for Open-Ended Game Agents
Xinyue Zheng, Haowei Lin, Kaichen He, Zihao Wang, Zilong Zheng, Yitao Liang
ICML Spotlight 2025
Minecraft Universe is introduced, a comprehensive evaluation framework set within the open-world video game Minecraft that combines a task composition mechanism capable of generating infinite diverse tasks with varying difficulty and a general evaluation framework that achieves 91.5% alignment with human ratings for open-ended task assessment
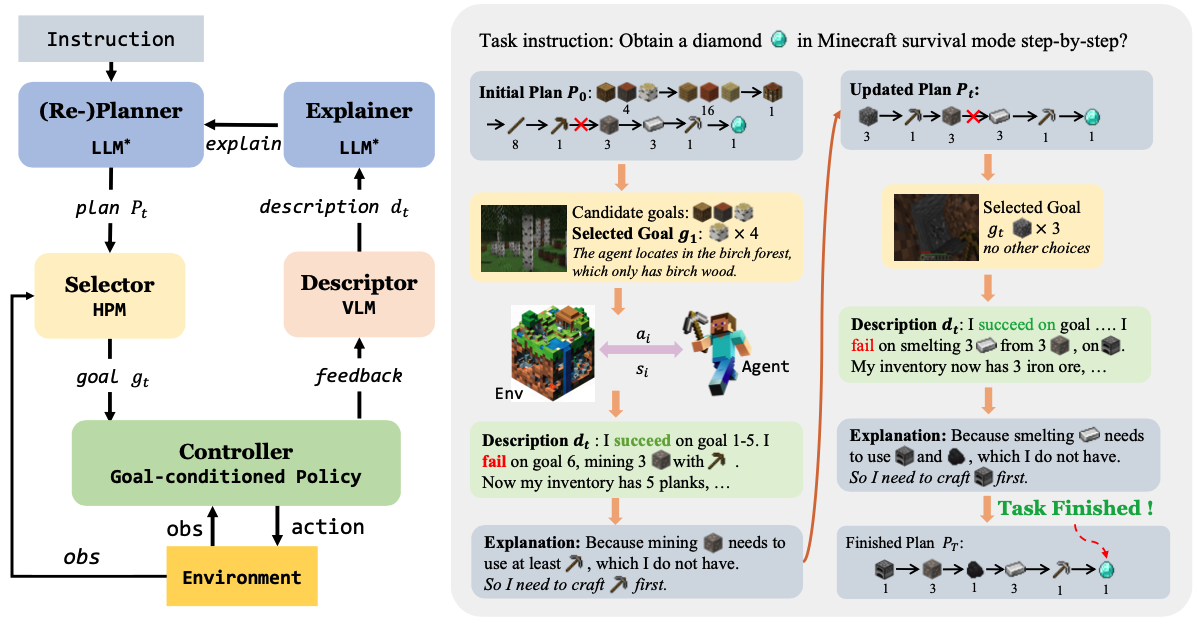
Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents
Zihao Wang, Shaofei Cai, Guanzhou Chen, Anji Liu, Xiaojian Ma, Yitao Liang
NeurIPS 2023 Best Paper Award, ICML 2023 TEACH Workshop
We investigate the challenge of task planning for multi-task embodied agents in open-world environments. We propose"Describe, Explain, Plan and Select"(DEPS), an interactive planning approach based on Large Language Models. DEPS facilitates better error correction on initial LLM-generated plan by integrating description of the plan execution process and providing self-explanation of feedback when encountering failures during the extended planning phases. Furthermore, it includes a goal selector, which is a trainable module that ranks parallel candidate sub-goals based on the estimated steps of completion, consequently refining the initial plan. Our experiments mark the milestone of the first zero-shot multi-task agent that can robustly accomplish 70+ Minecraft tasks and nearly double the overall performances.
Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents
Zihao Wang, Shaofei Cai, Guanzhou Chen, Anji Liu, Xiaojian Ma, Yitao Liang
NeurIPS 2023 Best Paper Award, ICML 2023 TEACH Workshop
We investigate the challenge of task planning for multi-task embodied agents in open-world environments. We propose"Describe, Explain, Plan and Select"(DEPS), an interactive planning approach based on Large Language Models. DEPS facilitates better error correction on initial LLM-generated plan by integrating description of the plan execution process and providing self-explanation of feedback when encountering failures during the extended planning phases. Furthermore, it includes a goal selector, which is a trainable module that ranks parallel candidate sub-goals based on the estimated steps of completion, consequently refining the initial plan. Our experiments mark the milestone of the first zero-shot multi-task agent that can robustly accomplish 70+ Minecraft tasks and nearly double the overall performances.
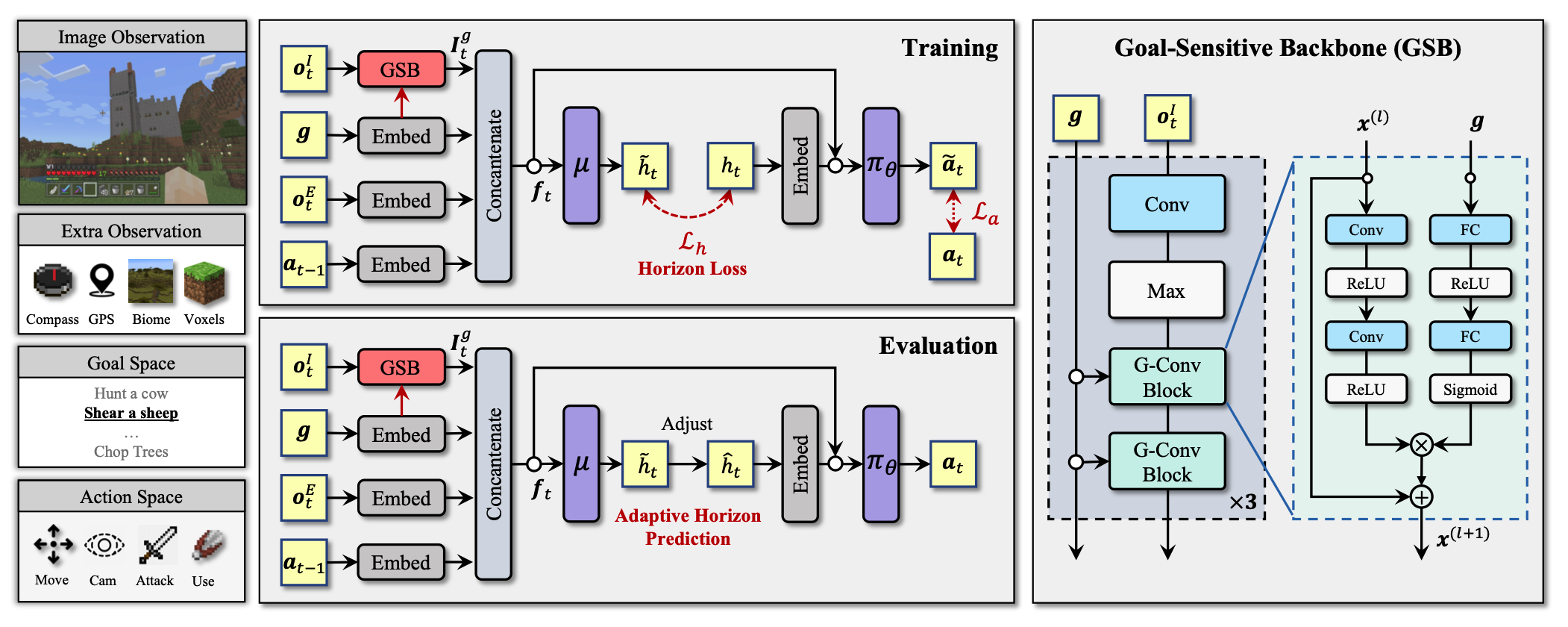
Open-World Multi-Task Control Through Goal-Aware Representation Learning and Adaptive Horizon Prediction
Shaofei Cai, Zihao Wang, Xiaojian Ma, Anji Liu, Yitao Liang
CVPR 2023
This work proposes Goal-Sensitive Backbone (GSB) for the policy to encourage the emergence of goal-relevant visual state representations in Minecraft and proposes an adaptive horizon prediction module that helps alleviate the learning uncertainty brought by the non-stationary dynamics
Open-World Multi-Task Control Through Goal-Aware Representation Learning and Adaptive Horizon Prediction
Shaofei Cai, Zihao Wang, Xiaojian Ma, Anji Liu, Yitao Liang
CVPR 2023
This work proposes Goal-Sensitive Backbone (GSB) for the policy to encourage the emergence of goal-relevant visual state representations in Minecraft and proposes an adaptive horizon prediction module that helps alleviate the learning uncertainty brought by the non-stationary dynamics

Learning Transformation-Predictive Representations for Detection and Description of Local Features
Zihao Wang, Chunxu Wu, Yifei Yang, Zhen Li
CVPR 2023
The task of key-points detection and description is to estimate the stable location and discriminative representation of local features, which is a fundamental task in visual applications and this work proposes to learn the transformation-predictive representations with self-supervised contrastive learning.
Learning Transformation-Predictive Representations for Detection and Description of Local Features
Zihao Wang, Chunxu Wu, Yifei Yang, Zhen Li
CVPR 2023
The task of key-points detection and description is to estimate the stable location and discriminative representation of local features, which is a fundamental task in visual applications and this work proposes to learn the transformation-predictive representations with self-supervised contrastive learning.
2022
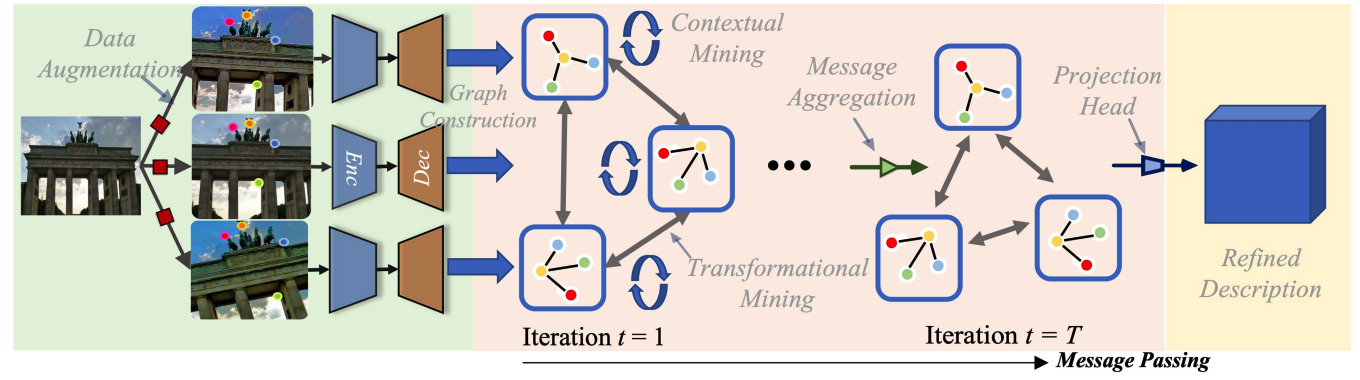
Graph-Based Contrastive Learning for Description and Detection of Local Features
Zihao Wang, Zhen Li, Xueyi Li, Wenjie Chen, Xiangdong Liu
TNNLS 2022
A self-supervised graph-based contrastive learning framework to train the model for local features, GCLFeat, which outperforms the state-of-the-art supervised baselines on diverse downstream benchmarks including image matching, 3-D reconstruction and visual localization.
Graph-Based Contrastive Learning for Description and Detection of Local Features
Zihao Wang, Zhen Li, Xueyi Li, Wenjie Chen, Xiangdong Liu
TNNLS 2022
A self-supervised graph-based contrastive learning framework to train the model for local features, GCLFeat, which outperforms the state-of-the-art supervised baselines on diverse downstream benchmarks including image matching, 3-D reconstruction and visual localization.
2021
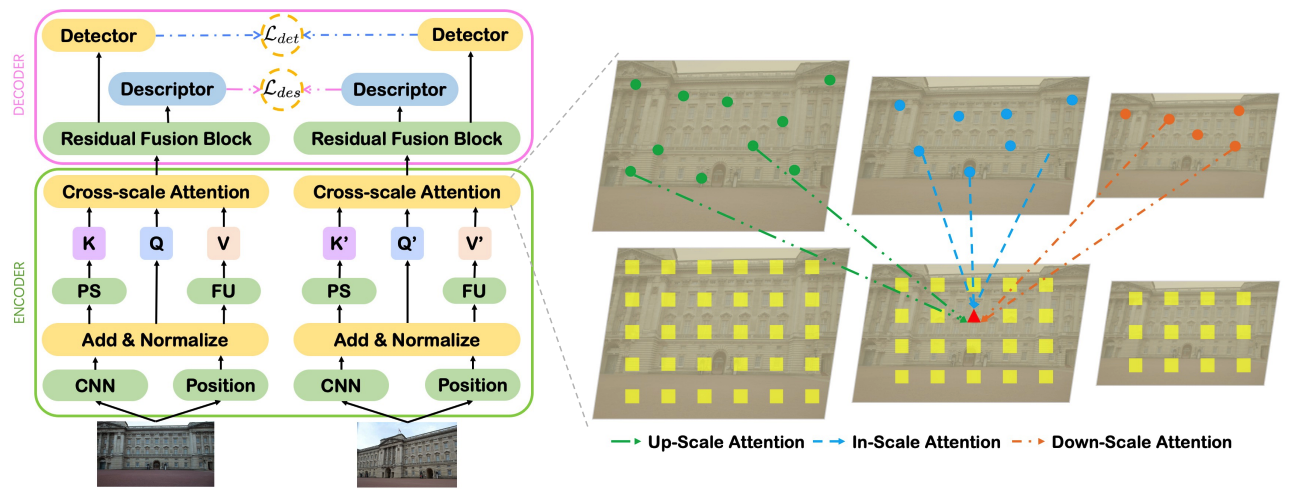
Local Representation is NOT Enough: Soft Point-wise Transformer for descriptor and Detector of Local Features
Zihao Wang, Xueyi Li, Zhen Li
IJCAI 2021
A novel Soft Point-Wise Transformer for Descriptor and Detector, simultaneously mining long-range intrinsic and cross-scale dependencies of local features, which outperforms the existing state-of-the-art methods on the image matching and visual localization benchmarks.
Local Representation is NOT Enough: Soft Point-wise Transformer for descriptor and Detector of Local Features
Zihao Wang, Xueyi Li, Zhen Li
IJCAI 2021
A novel Soft Point-Wise Transformer for Descriptor and Detector, simultaneously mining long-range intrinsic and cross-scale dependencies of local features, which outperforms the existing state-of-the-art methods on the image matching and visual localization benchmarks.